- fjroar
- 25 ago 2021
- 6 Min. de lectura
Hay un par de motivos importantes a la hora de escribir este post. Uno de ellos es tratar de hacer realmente entendible qué hay detrás de un modelo tipo knn o k-vecinos más próximos (en español) y otro no menos interesante es entender porque estos modelos, cuando se aplican a grandes cantidades de datos pueden resultar lentos e ineficientes.
El modelo knn no creáis que se ha inventado con la movida del ML y demás, sino que viene de principios de los 50 y fueron desarrollados por Evelyn Fix y Joseph Hodges.
Hay muchas variantes de este modelo y aquí se va a considerar sólo 1, quizás la más avanzada que es la que creo que es más esclarecedora una vez que se entiende, así pues, se considera que se tiene una variable explicada de tipo continuo como pueda ser la variable target del conocido dataset Boston que es una estimación del precio del metro cuadrado de la vivienda en función de otras 13 variables explicativas.
Para hacer más sencillo la comprensión de este algoritmo, de las anteriores 13 variables, se van a considerar sólo 2, las denominadas RM (número medio de habitaciones) y AGE (proporción de unidades ocupadas por sus propietarios construidas antes de 1940) que se ha visto que aparecen como significativas en cualquier regresión lineal.
Dado que es un conjunto muy limpio, no hay que hacer ningún tratamiento a priori especial con estas variables. Se hace una separación training-test del tipo 80%-20% que si se representa (tranquilos, he fijado una semilla de aleatorización para que podáis reproducirlo …) se obtiene la siguiente representación siempre y cuando se haya estandarizado las variables (en el training y aplicada dicha estandarización en el test):

Observación: Tanto el anterior dibujo, como análisis que aquí se muestran están realizados bajo entorno Spyder y os lo podéis descargar de mi git en: https://github.com/FJROAR/Ejemplo-Blog-KNN
Pues vamos a entrar en materia ¿Cómo funciona esto del knn en una variable continua? Para empezar a hablar, el entrenamiento de un knn no guarda una mayor dificultad ya que prácticamente lo que se hace es “memorizar instancias” qué, ¿Qué es eso de memorizar instancias? Pues que no cunda el pánico, simplemente lo que se hace en la fase de entrenamiento es guardar (en memoria o algún sitio, …) los puntos azules (en este caso el 80% de los datos) con todos sus valores (explicativa y target) y ya no se hace nada más, como veis el tema es rápido, sin embargo, ahora llega “el momento de la verdad” ¿Cómo predice un knn cuando llega un nuevo dato? “¡Eh, amigo!, aquí la cosa, aunque creo que se va a entender, es algo más enrevesado”.
En primer lugar, debe tenerse el dato de cuántos serán los vecinos para la interpolación, en este caso supongamos que k = 1, por tanto, el primer paso a dar es calcular la distancia de ese punto a todos los puntos del training para obtener el punto más cercano posible. Una vez obtenido este punto, el valor que se interpola es el que está almacenado en el training. En el supuesto de que k = 2, se hace la misma operación hasta que se consideran a los 2 puntos más cercanos posibles y en este caso se asocia una media de valores y así sucesivamente.
Como puede observarse, aunque estas operaciones son fáciles de entender, para un procesador resulta complicado el tema de las operaciones del cálculo de distancia, ya que para cada dato debe hacer tantos cálculos como datos existe en el training y por tanto imaginaros que estamos ante un dataset de tamaño medio de unos 100.000 registros donde se aplica un 70%-30%, el número de operaciones para predecir el test sería del orden de 2100 mill y eso que para muchos esto no es más que un aperitivo en el mundo del Big Data. Además está el problema de que cada vez que entre un dato nuevo, si se pone el knn en producción habría que esperar a que haga sus 70.000 operaciones y “resto de cositas” para tener un valor, lo que puede resultar en unos segundos que en el caso de ser un proceso de entrada continuo de datos, podría hacer colapsar el sistema. Por tanto aquí está la debilidad de este tipo de modelos que hay que tenerla muy en cuenta en función del problema que se vaya a tratar.
Siguiendo con el ejemplo de los datos de Boston, aquí no se tiene este problema ya que hay tan sólo unas 506 observaciones, cuyas variables estandarizadas han sido ya representadas anteriormente separando por training y por test. Para entender lo que he dicho anteriormente vamos a ver qué es lo que hace el algoritmo exactamente. Supongamos que k = 1 y consideramos el punto del test normalizado más a la derecha:

¿Qué valor se le va a asociar? Pues bien, habiendo elegido una distancia como es la euclídea, se tiene que buscar el punto azul más cercano. Si agudizamos bien la vista, se observa que sobre el punto rojo que está al lado parece que existe un punto azul por debajo, esto se puede observar en la siguiente representación ordenada de los dataset test y training ordenados de menor a mayor por la variable RM:

El punto de interés es justamente el que tiene por índice el número 25 en el X_test_norm (buena idea esta de los índices en Python, por cierto) Y el punto más cercano a este pero en X_train_norm es el que tiene por índice el número 218, de hecho si observamos en X_test_norm, se observa que el punto que tiene por índice el número 96, tiene las mismas coordenadas que el anterior, es decir, los puntos están superpuestos y como el rojo cae encima del azul, de ahí el hecho que no se vea este último.
Pues bien, ¿Cuál es el valor que se le asociaría al punto anterior bajo un 1-nn? En este caso, dado que ya se ha averiguado el punto más cercano, se va al dataset training y es cuando se mira el valor en el target en el dataset y_train que resulta ser (buscando por el índice 218) el valor 11.9, para verlo en el código se genera una variable kpred1 donde en su valor índice 25, se obtiene dicho valor de hecho, como habrá deducido el lector, también en el índice con valor 96, el valor va a ser exactamente el mismo por razones obvias. Y ahora se da un pasito más ¿Cuál es el valor que se asociaría al punto anterior bajo un 2-nn? En este caso hay que buscar el 2º punto más cercano que resulta ser el punto azul más a la izquierda cuyo índice en X_train_norm es 165, cuyo valor de target, si se mira en y_train (en el índice 165) es igual a 27.5, por lo que la predicción a asociar en este caso en el índice 25 de y_test debe ser la media 11.9 y 27.5 que resulta ser igual a 19.7 tal y como se observa:

Llegados a este punto sabemos cómo actúa un knn y cómo asocia sus valores en el caso de una variable target de tipo continuo, pero se ha comentado que hay una limitación y es cuando el dataset es muy grande, pero ¿Y cuando tal limitación no existe? ¿Funciona bien para casos como el aquí tratado?
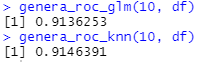
Bueno, en el código hacía una comparación usando esas mismas variables para una regresión lineal y probando con varias opciones para k, en dicho test obtuve los siguientes resultados cuando se había aplicado una estandarización de variables:

Mientras que, sin estandarizar variables, los resultados habían sido los siguientes:

Por lo que en definitiva cabe concluir las siguientes líneas generales:
-Los knn pueden dar lugar a problemas cuando se trata de modelizar datos masivos debido a que el cálculo de distancias es un proceso intensivo en cálculo, además adolecen del problema del curse of dimensionality (que no se ha tratado), con lo que son efectivos si hay pocas variables explicativas que rellenen suficientemente el espacio
-Como regla general, un preprocesado de variables es recomendable en estos modelos para que funcionen correctamente, observándose efectos muy negativos cuando las escalas de las variables son dispares
-Con pocos datos, estos modelo pueden mejorar a las regresiones lineales, pero debe hacerse comprobación con varios órdenes k, no hay regla general de elección de dicho parámetro y se recomienda en aplicaciones reales, si es que no hay mucho datos, hacer uso de cross-validaciones (que no se ha tratado aquí)